kuber(netes)less
No kubectl, no manifests, no explaining what a namespace is..
I wanted to know what it actually takes to hide Kubernetes from the people running workloads on it. Not abstract it a little, hide it entirely.
The target experience was something like Cloud Run/Heroku: give it an image, get back a URL, scale to zero when there’s no traffic. The platform handles isolation, routing, and resource limits. The user handles their app. That’s the contract.
I built this as a weekend project to find out where that contract breaks down.
kuberless deploy ghcr.io/example/hello:latest --name myapp --port 8080
# App is ready: https://hello.tenant-my-org.example.com
Four components
The CLI and Frontend face the user. The API-server and Operator run the platform.
App CR"] CRD --> OP[Operator] OP -.->|writes status| CRD OP --> T["Namespace
Capsule
Cilium Policy
ResourceQuota"] OP --> A["Knative Service
DomainMapping"] style CLI fill:#d4edda,stroke:#28a745,color:#000 style UI fill:#d4edda,stroke:#28a745,color:#000 style API fill:#d4edda,stroke:#28a745,color:#000 style OP fill:#d4edda,stroke:#28a745,color:#000
The CLI and frontend are thin clients. They make API calls and surface the result.
The API server handles auth, validation, and state. It writes to Postgres and creates the custom resources.
The operator watches the CRDs and does the actual work: namespaces, network policies, resource quotas, Knative Services. It writes status back as things change.
The API server and operator share nothing except the CRDs. My first instinct was letting the API server talk to Kubernetes directly, but partial failures quickly require retries and reconciliation. That logic belongs in the operator.
API Server → CR → Operator → infra
← status ←
The serverless runtime
The serverless runtime was the part I was most curious about. Knative handles this quite well out of the box. Three annotations configure the core behavior:
autoscaling.knative.dev/min-scale: "0"
autoscaling.knative.dev/max-scale: "10"
autoscaling.knative.dev/target: "100"
When a pod scales to zero and a request arrives, the Activator intercepts it, wakes a pod via the autoscaler, and buffers the request until the pod is ready. After that, traffic routes directly to the pod.
The target annotation controls concurrent requests per pod, not RPS; scale-up reacts to spikes, while scale-down uses a stabilization window to avoid thrashing.
Cold starts depend on image pull and pod startup, but on a warm node, the Activator buffers requests for under two seconds, ensuring traffic isn’t dropped even if the pod wasn’t running.
The operator
Inside the operator, each sub-resource gets its own reconciler:
TenantReconciler
├── NamespaceReconciler # creates tenant-{name} namespace
├── CapsuleReconciler # creates Capsule Tenant CR, sets RBAC
├── CiliumReconciler # creates CiliumNetworkPolicy
└── ResourceQuotaReconciler # applies CPU/memory limits by plan
AppReconciler
├── KnativeReconciler # creates/updates/deletes Knative Service
└── DomainReconciler # syncs custom DomainMappings
When the Cilium policy had a subtle bug, I went to one file. Same when Knative behavior was unexpected.
The operator creates resources from three external projects: Knative, Capsule, and Cilium. Importing their Go types directly causes dependency conflicts: knative.dev/serving and capsule.clastix.io both pull in different versions of controller-runtime. This is a common problem when writing operators that touch multiple CRD-owning projects. Their module graphs don’t compose cleanly.
The alternative is unstructured.Unstructured: build and read resources as nested maps instead of typed structs. You lose type safety and compile-time validation, but the operator compiles cleanly regardless of what upstream projects do to their dependency trees.
obj := &unstructured.Unstructured{}
obj.SetGroupVersionKind(schema.GroupVersionKind{
Group: "serving.knative.dev",
Version: "v1",
Kind: "Service",
})
obj.SetName(app.Name)
obj.SetNamespace(tenantNamespace)
unstructured.SetNestedField(obj.Object, "0", "spec", "template", "metadata", "annotations", "autoscaling.knative.dev/min-scale")
The downside is practical: a mistyped field path compiles fine and blows up at runtime. For a side project touching three different CRD ecosystems, it’s the right call. In production you’d want generated clients or at least integration tests that catch the field paths early.
The API server
My instinct was to store everything in Postgres, but the app URL comes from Knative, phase from the CRD status, instance count from Knative Service conditions. None of that lives in Postgres. So GET /apps/:id has to go to two places.
Postgres stores things that change because a user changed them: tenant config, env vars, billing plan, API keys. Kubernetes stores things that change because the cluster changed. The API server merges them at read time:
func (s *AppService) Get(ctx context.Context, appID string) (*App, error) {
app, _ := s.store.GetAppByID(ctx, appID)
s.enrichWithK8sStatus(ctx, app, tenantName)
return app, nil
}
No sync needed. Postgres is the source of truth for config, Kubernetes for status. If Kubernetes is slow or unavailable, status fields come back empty but config still loads.
From the user’s side, that looks like: app deployed, status unknown. The platform hides Kubernetes well enough that they can’t tell what happened, but not well enough that it doesn’t matter.
Isolation
Multi-tenancy required four separate things.
Namespaces give you naming isolation; resources don’t collide. But a pod in one namespace can still freely curl a pod in another. The namespace boundary doesn’t stop network traffic.
CiliumNetworkPolicy enforces network isolation. Each namespace gets a policy that allows intra-namespace traffic, allows ingress from the Knative and platform namespaces, and blocks everything else. The key rule is RFC 1918 exclusion on egress: cluster-internal IPs fall in private address ranges, so blocking those blocks cross-tenant traffic while leaving internet calls open.
// unstructured representation of CiliumNetworkPolicy egress rule
"toCIDRSet": []interface{}{
map[string]interface{}{
"cidr": "0.0.0.0/0",
"except": []interface{}{
"10.0.0.0/8",
"172.16.0.0/12",
"192.168.0.0/16",
},
},
},
One gotcha:
toCIDRlooks similar totoCIDRSetbut doesn’t support exclusions. The deny rules get silently dropped.
ResourceQuota caps CPU and memory per namespace. Network isolation stops cross-tenant traffic; quotas stop one tenant from consuming all the cluster’s compute.
Capsule handles RBAC. Each tenant gets a Capsule Tenant CR scoping their permissions to their own namespace, without touching anything cluster-wide.
┌─────────────────────────────────────────────────────┐
│ Capsule (RBAC) │
│ ┌───────────────────────────────────────────────┐ │
│ │ ResourceQuota (CPU/memory limits by plan) │ │
│ │ ┌─────────────────────────────────────────┐ │ │
│ │ │ CiliumNetworkPolicy (cross-tenant deny) │ │ │
│ │ │ ┌───────────────────────────────────┐ │ │ │
│ │ │ │ Namespace (naming isolation) │ │ │ │
│ │ │ └───────────────────────────────────┘ │ │ │
│ │ └─────────────────────────────────────────┘ │ │
│ └───────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
Four layers is what it actually takes on a shared cluster, and every one of them is invisible to the user by design, which also means none of them are debuggable by the user when they break.
Finalizers just handle deletion, right?
Kubernetes garbage collection removes child resources when their namespace disappears, but skips finalizers in the process, so cleanup logic never runs. Delete the namespace before the App CRs and Knative Services and DomainMappings get orphaned. The right order:
Tenant: set phase=Deleting
→ delete all App CRs, wait for them to finish
App: delete DomainMappings
→ delete Knative Service
→ remove app finalizer
→ delete CiliumNetworkPolicy
→ delete Capsule Tenant
→ delete namespace
→ remove tenant finalizer
One that took embarrassingly long: an App CR stuck in Deleting because its Knative Service had already been manually removed. The finalizer was waiting for something that no longer existed. Treating 404 as success unblocked it:
err := r.Delete(ctx, ksvc)
if err != nil && !errors.IsNotFound(err) {
return err
}
The result
kuberless deploy returns a URL. The frontend shows the app status, instance count, and lets you set env vars, pause, resume. Scaling happens in the background. Hit the URL after a few minutes idle and you’ll wait a second or two while the pod comes back up.
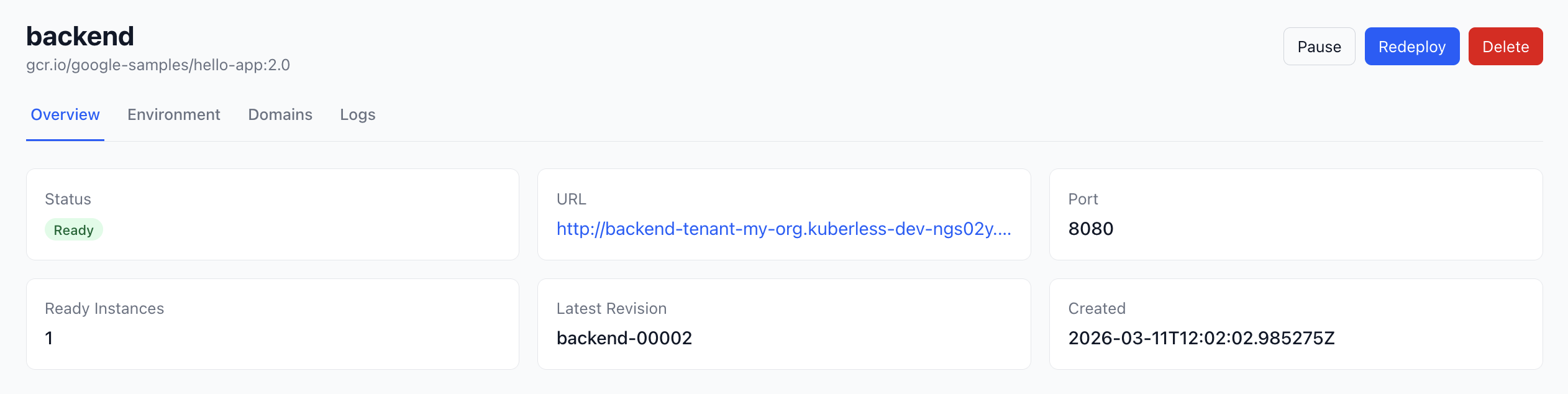
The gaps are real. No databases, cron jobs, or background workers. Error messages are rough. A ResourceQuota failure surfaces as “deployment failed” with nothing else; the actual event is in the Kubernetes log but never reaches the user. When something breaks deep in Knative or Cilium it lands on whoever’s running the platform.
Is hiding Kubernetes even the right answer?
While building this I kept thinking: a Project Manager with a vibecoded app and Claude Code doesn’t necessarily need this type of platform. Claude Code can write manifests, run kubectl, read pod events. It’s actually pretty good at this.
The platform’s advantage is scope control. Claude Code calls kuberless deploy, gets a URL or an error, and can’t touch other tenants’ workloads or anything cluster-wide. The tradeoff is that it can’t go beyond what the platform supports: no databases, no cron jobs, and when something breaks deep in Knative it has no way to surface why.
Raw Kubernetes gives Claude Code full access, which means full blast radius. A confused prompt or a hallucinated resource name on a shared cluster is a bad time. There’s also a conventions problem: a platform encodes how things should be named, labelled, and structured. Without that, Claude Code makes its own choices, which might work, but produces infrastructure nobody can debug later. You can encode those conventions as skills or plugins, but at that point you’re building a platform anyway, just in prompts instead of a CLI.
A dedicated cluster per PM removes the shared-tenant risk, but you’re still paying for a control plane and node pool whether anything is running. The conventions problem doesn’t go away either.
I’m not sure which approach is better. The platform gives you a bounded surface area but leaks at the edges. Raw Kubernetes gives you full power with full blast radius. A dedicated cluster eliminates cross-tenant risk but doesn’t eliminate complexity, just moves it.
Want to poke at it?
Most of the engineering was figuring out what each layer doesn’t cover: namespaces don’t isolate traffic, network policies don’t limit resources, quotas don’t handle permissions. The original goal was to hide all of that behind a single command.
The source is on GitHub. This is a learning project, not something you should run in production. No backup strategy, no monitoring, error handling is minimal. But it’s complete enough to deploy and poke at.